Introducing NUPunkt and CharBoundary: two specialized libraries that dramatically improve sentence boundary detection in legal documents.
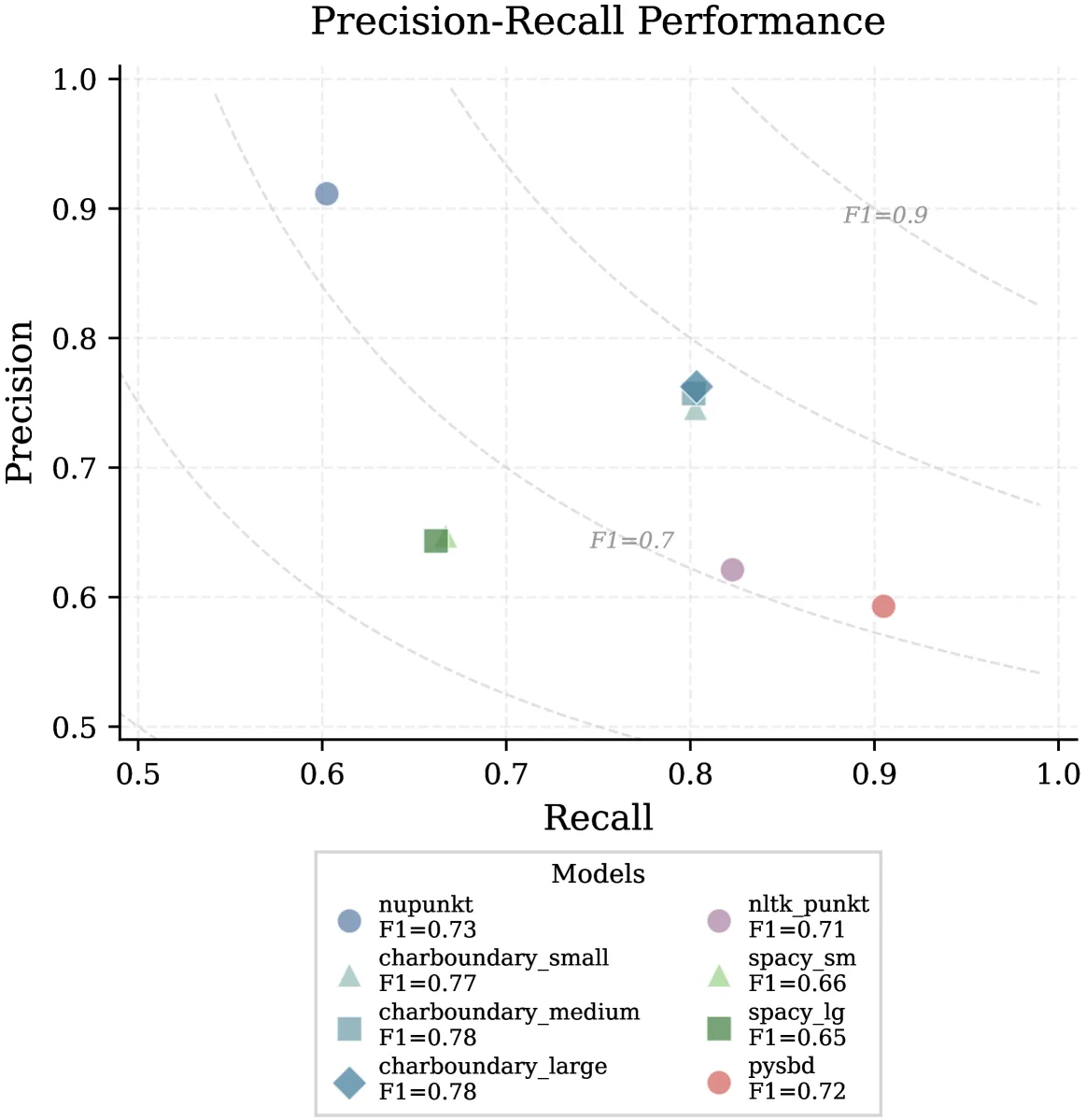
We’re excited to announce the release of two specialized libraries for legal sentence boundary detection: NUPunkt and CharBoundary, along with a comprehensive benchmark dataset.
Try It Yourself
Visit our interactive visualization tool to test these models with your own legal text and see how they compare to standard approaches.
Our research paper, “Precise Legal Sentence Boundary Detection for Retrieval at Scale: NUPunkt and CharBoundary”, documents the significant improvements these tools bring to legal text analysis.
Accurate sentence boundary detection is a fundamental challenge for natural language processing systems, particularly in specialized domains like law. Legal text presents unique challenges with:
When legal text is incorrectly segmented at sentence boundaries, critical information is fragmented, context is lost, and downstream applications like retrieval-augmented generation (RAG) systems suffer dramatically reduced performance.
We’re addressing this challenge with two different approaches, each with unique advantages:
NUPunkt is a pure Python library with zero external dependencies, making it ideal for high-throughput production environments:
pip install nupunktfrom nupunkt import sent_tokenize
text = "See Smith v. Jones, 123 F.2d 456, 789 (7th Cir. 2010). The court cited U.S.C. § 101 et seq. in its analysis."
sentences = sent_tokenize(text)
print(sentences)
# ['See Smith v. Jones, 123 F.2d 456, 789 (7th Cir. 2010).', 'The court cited U.S.C. § 101 et seq. in its analysis.']CharBoundary takes a character-level machine learning approach for even greater accuracy:
pip install charboundary[onnx]from charboundary import get_large_onnx_segmenter
segmenter = get_large_onnx_segmenter()
text = "Pursuant to Rule 12(b)(6), defendant Corp. Inc. moves to dismiss. See Twombly, 550 U.S. at 555-56."
# Get sentence boundaries with character-level precision
spans = segmenter.get_sentence_spans(text)
print(spans)
# [(0, 65), (65, 98)]
# Get the actual sentences
sentences = segmenter.segment_to_sentences(text)
print(sentences)
# ['Pursuant to Rule 12(b)(6), defendant Corp. Inc. moves to dismiss.', 'See Twombly, 550 U.S. at 555-56.']To enable further research in this area, we’ve released a high-quality benchmark dataset:
This dataset is available on HuggingFace.
Our research shows that improvements in sentence boundary detection have a multiplicative effect on downstream applications:
Both libraries are available now under the MIT license:
We invite researchers, legal technologists, and developers to try these tools, contribute to their development, and build upon this work to advance the state of legal natural language processing.