Introducing the KL3M Data Project: a comprehensive collection of legally sound training resources for large language models spanning 132+ million documents.
Today, we’re excited to announce the release of the KL3M Data Project, a comprehensive collection of copyright-clean training resources for large language models. Our research paper details how we’ve created legally sound resources spanning 132,349,390 documents across 16 different data sources.
Explore the Data
Visit our interactive data gallery to explore individual documents with our interactive tool or browse our public datasets on HuggingFace.
Recent litigation and regulatory scrutiny have highlighted significant legal uncertainties around AI training data:
These issues create significant risks for AI developers and users alike, potentially leading to legal liability, model removal, or retraining requirements.
The KL3M Data Project takes a fundamentally different approach:
By building on positive legal rights and consent rather than uncertain fair use arguments, we establish an alternative paradigm for ethical AI data collection.
What sets the KL3M Data Project apart is our commitment to releasing the complete data pipeline at all stages. This public release represents a snapshot of our ongoing collection efforts, with new documents and resources being added daily:
Original Documents (~28 TB compressed)
Extracted Content
Pre-tokenized Resources
This approach enables unprecedented research transparency, reproducibility, and auditing capabilities. Researchers can trace any model output back to source documents, verify processing methods, and create alternative extraction approaches.
The KL3M Data Project encompasses materials at a scale suitable for serious AI development:
Total Documents: 132,349,390 (growing daily)
Storage Size: ~28 TB compressed (as of April 2025)
Token Count: 1.35 trillion across 16 sources
Our resources span diverse domains:
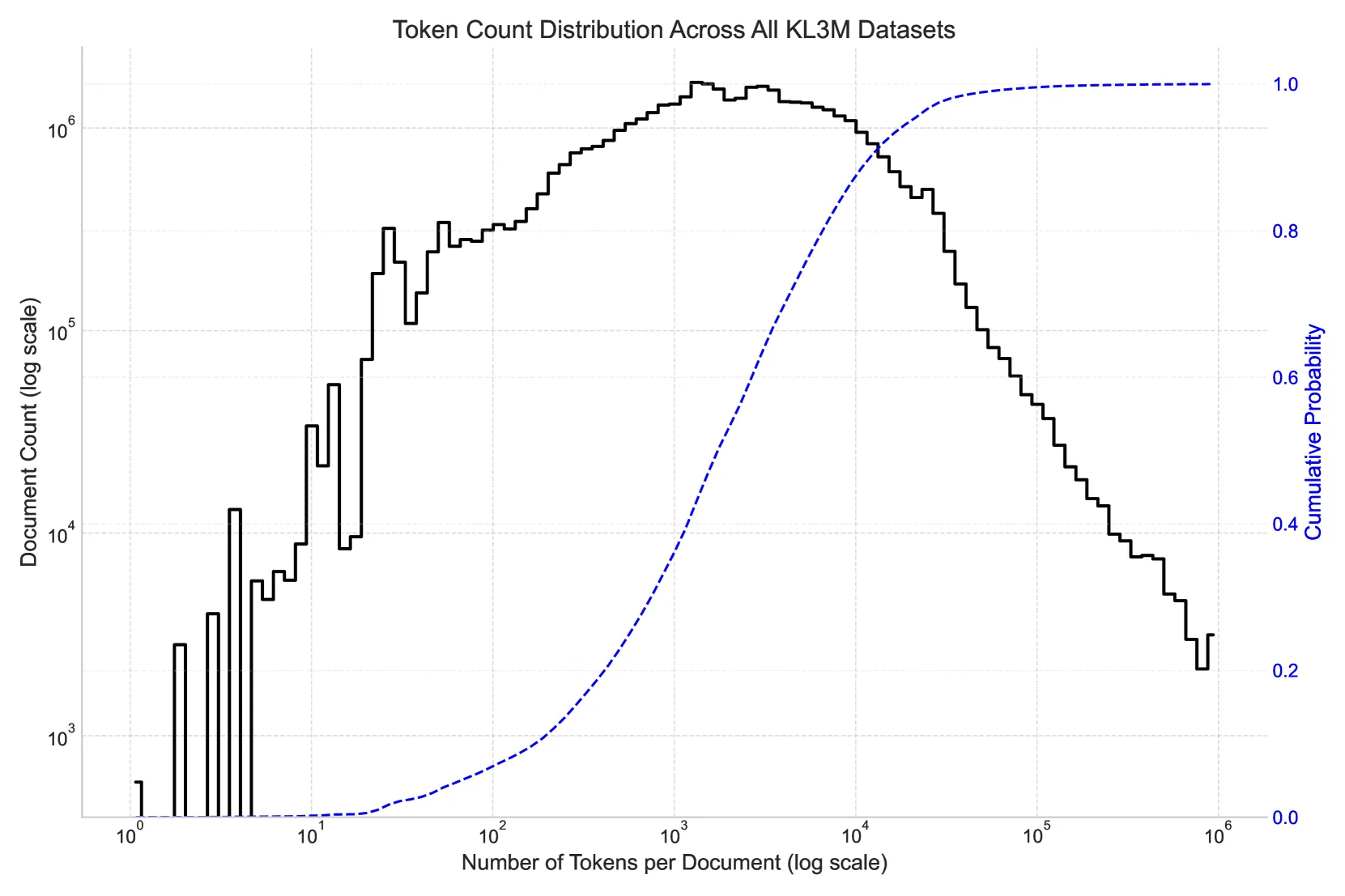
The document collection includes texts of all lengths, with a mean of 6,237 tokens and median of 1,855 tokens per document. Over 200,000 documents exceed 100,000 tokens in length, making this dataset valuable for long-context model training.
Here are some highlights from our collections currently available on HuggingFace:
A comprehensive snapshot of our data containing 57.8M rows of tokenized documents from various sources, ready for model training.
1.45M corporate agreements extracted from SEC filings, providing rich examples of legal and financial language.
A sample dataset containing 3,491,369 rows from government records, demonstrating how the data can be structured for supervised fine-tuning tasks.
We’ve made the KL3M Data Project accessible at each processing stage through multiple channels:
Amazon S3: s3://data.kl3m.ai/
/documents/{source}//representations/{source}//parquet/{source}/HuggingFace:
Interactive Gallery:
GitHub:
The KL3M Data Project supports a wide range of AI development needs:
Ready to explore legally and ethically sound AI training data?
We invite researchers, developers, and AI practitioners to build upon these resources as we work toward more ethical, legally sound AI development practices. The KL3M Data Project is a living dataset that continues to grow, with new documents, datasets, and tools being released regularly.