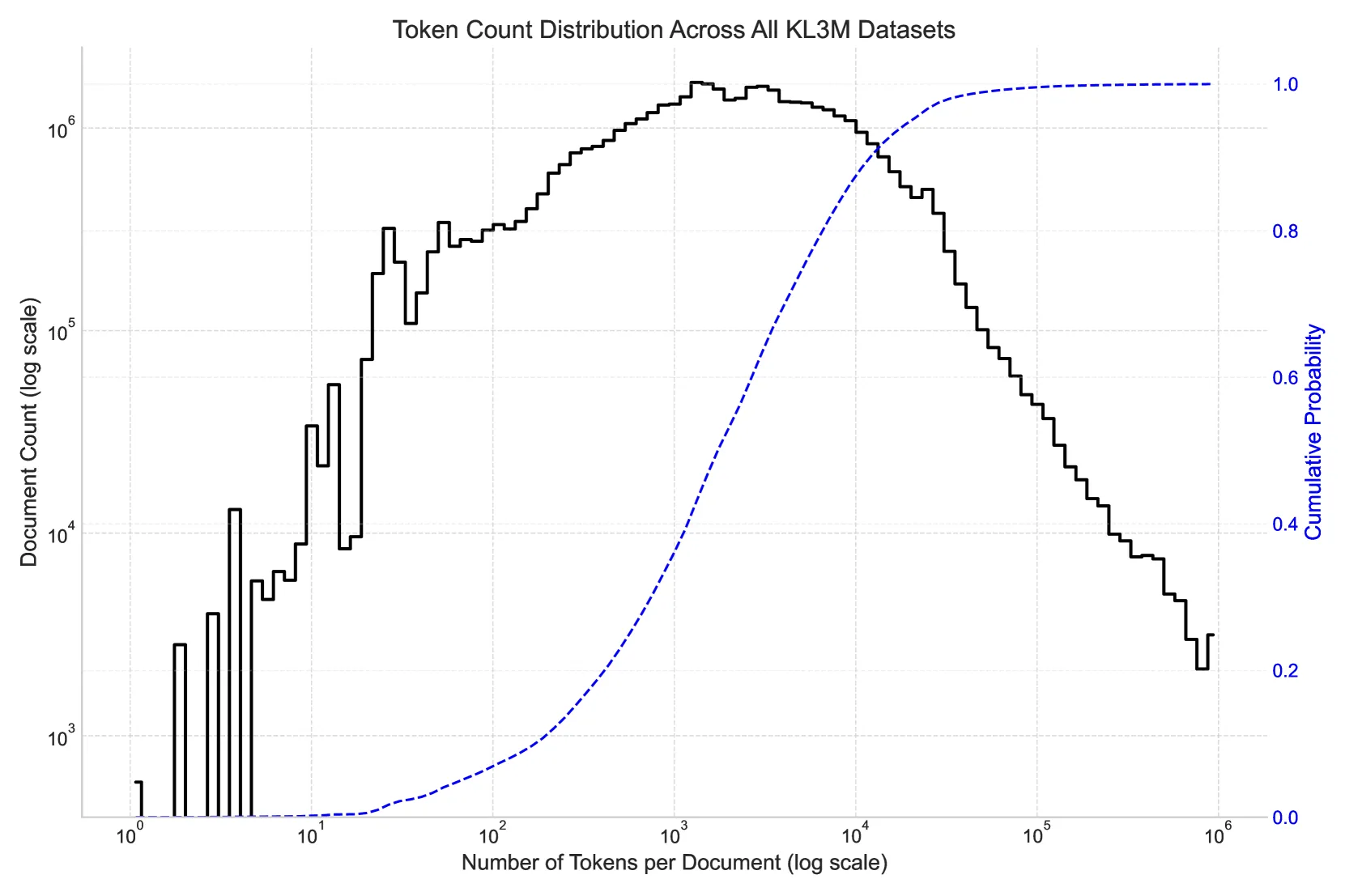
The KL3M Data Project: Clean Training Resources for LLMs
The ALEA Institute has released the KL3M Data Project, a comprehensive collection of copyright-clean training resources for large language models. This project provides a systematic approach to creating legally sound training data for AI systems, establishing an alternative paradigm focused on positive legal rights and consent rather than uncertain fair use arguments.
Explore the Data on HuggingFace: Browse our public datasets or visit gallery.kl3m.ai to explore individual documents with our interactive tool.
Addressing Legal and Ethical Challenges in AI Training
Recent legal challenges surrounding AI training data have highlighted the urgent need for ethically sourced, legally defensible content. The KL3M Data Project tackles this problem head-on by:
- Developing a systematic legal risk assessment protocol for training data
- Focusing on government documents, public domain works, and other legally permissible sources
- Providing transparent provenance and licensing information
- Releasing complete data collection and processing pipelines
- Making all resources available under permissive CC-BY terms
Comprehensive Three-Stage Pipeline
The KL3M Data Project offers an unprecedented scale of legally sound resources through a unique three-stage pipeline. This public release represents the current state of our ongoing collection efforts, with new documents and resources being added daily:
- Original Documents: Complete raw documents as initially collected (~28 TB compressed, substantially larger when uncompressed)
- Extracted Content: Clean, processed text/markdown/HTML extracted from originals
- Pre-tokenized Resources: Ready-to-use tokenized data for immediate model training
This complete pipeline is essential for:
- Research Transparency: Verify exactly how data was processed
- Reproducibility: Recreate the exact training data from original sources
- Auditability: Trace any model output back to its source documents
- Customization: Create different extraction methods on the original documents
Key Datasets
- Court Listener (CAP): Federal and state court opinions and decisions
- Court Dockets: Legal proceeding records and filed documents
- RECAP: Public records from the federal judiciary
- RECAP Documents: Documents from federal court cases
- EDGAR Filings: Corporate agreements and disclosures from the SEC
- Federal Register: Official government regulatory publications
- US Code: United States federal statutory code
- GovInfo: Official publications from all three branches of government
- Electronic CFR (eCFR): Federal regulatory text and amendments
- USPTO Patents: Patent applications and granted patents
- Regulations.gov: Proposed and final regulatory documents
- .gov Websites: U.S. government domain website content
- EU Official Journal: Legislative and official publications from the European Union
- UK Legislation: Acts of Parliament and statutory instruments
- Federal Depository Library: Government publications and documents
Versatile Applications
The KL3M Data Project supports a wide range of AI development needs:
- Pre-training: Create foundational models with legally sound data
- Fine-tuning: Specialize models for specific domains
- Benchmarking: Evaluate model performance on real-world documents
- Domain-specific tasks: Support legal, financial, and regulatory applications
- Research: Enable studies on document characteristics and linguistic patterns
Note: The KL3M Data Project is a living dataset. New documents, datasets, and tools are being added regularly as our collection and processing efforts continue.