Precision tools for legal text analysis with NUPunkt and CharBoundary libraries.
In collaboration with:
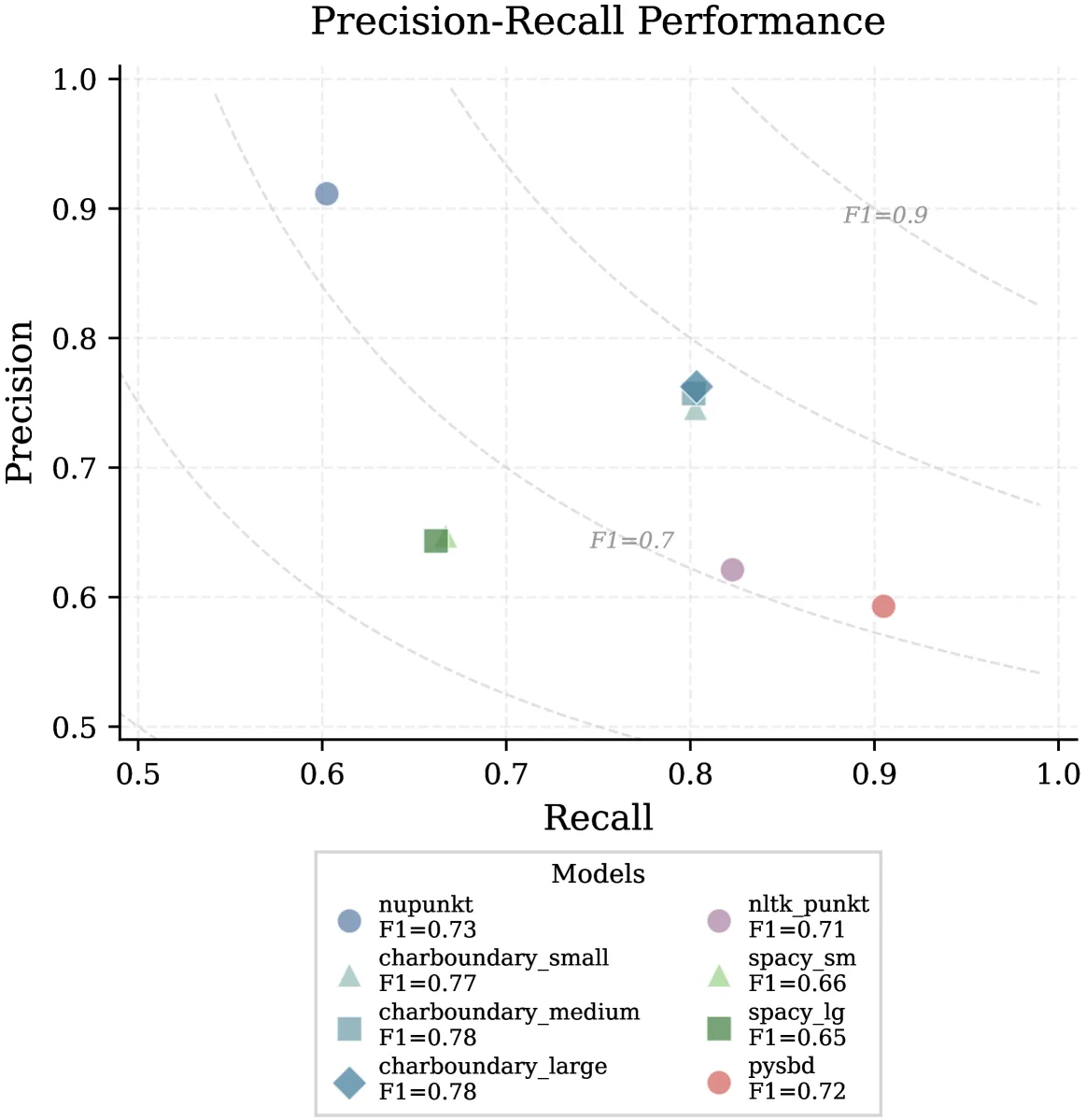
The ALEA Institute has released two specialized libraries for legal sentence boundary detection: NUPunkt and CharBoundary, along with a comprehensive benchmark dataset.
Try Our Interactive Visualization: Explore our interactive demonstration site to visualize how different models handle complex legal sentences in real-time.
These tools solve a critical problem in legal natural language processing: accurately identifying where sentences begin and end in complex legal documents containing specialized citations, abbreviations, and intricate sentence structures.
Accurate sentence boundary detection is the foundation of many downstream NLP tasks, particularly for retrieval-augmented generation (RAG) systems in the legal domain. When legal text is incorrectly segmented:
Our research shows that each percentage improvement in precision yields exponentially greater reductions in context fragmentation for legal document analysis.
To enable further research, we’ve released a comprehensive benchmark dataset for legal sentence and paragraph boundary detection:
Don't be shy. We'd love to hear from you.