What we're reading, thinking, and doing.
A new MCP server for AI agents, alongside an updated public API and Python library, make FOLIO's legal ontology easier than ever for courts and legal organizations to adopt.
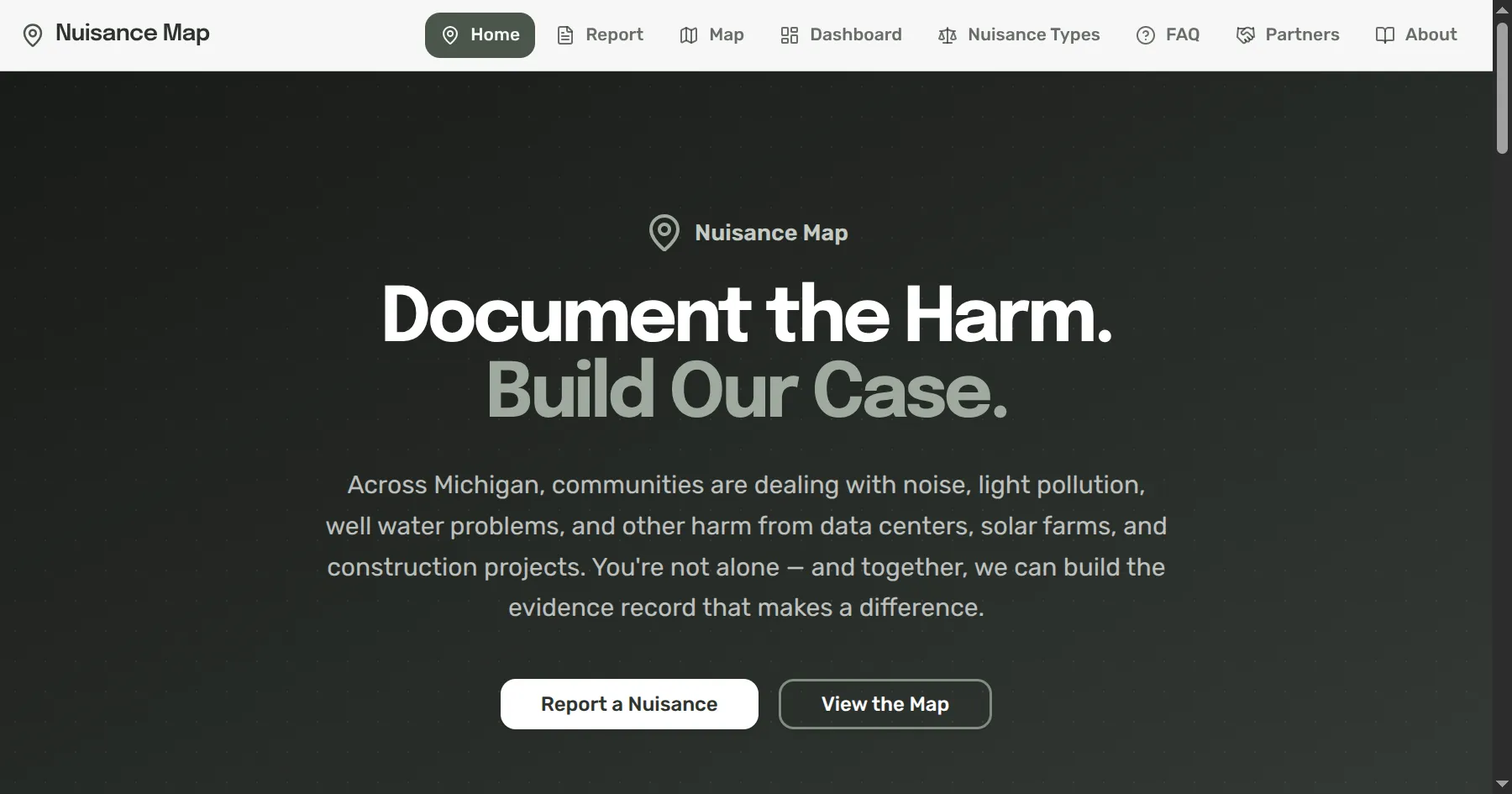
ALEA Institute launches the Nuisance Map, an open-source tool for Michigan residents to document nuisance impacts from data centers and infrastructure development, as part of an expanded community engagement initiative focused on transparency and balanced development.

The ALEA Institute has received its official IRS determination letter granting 501(c)(3) tax-exempt status as a public charity, with an effective date of August 15, 2024.
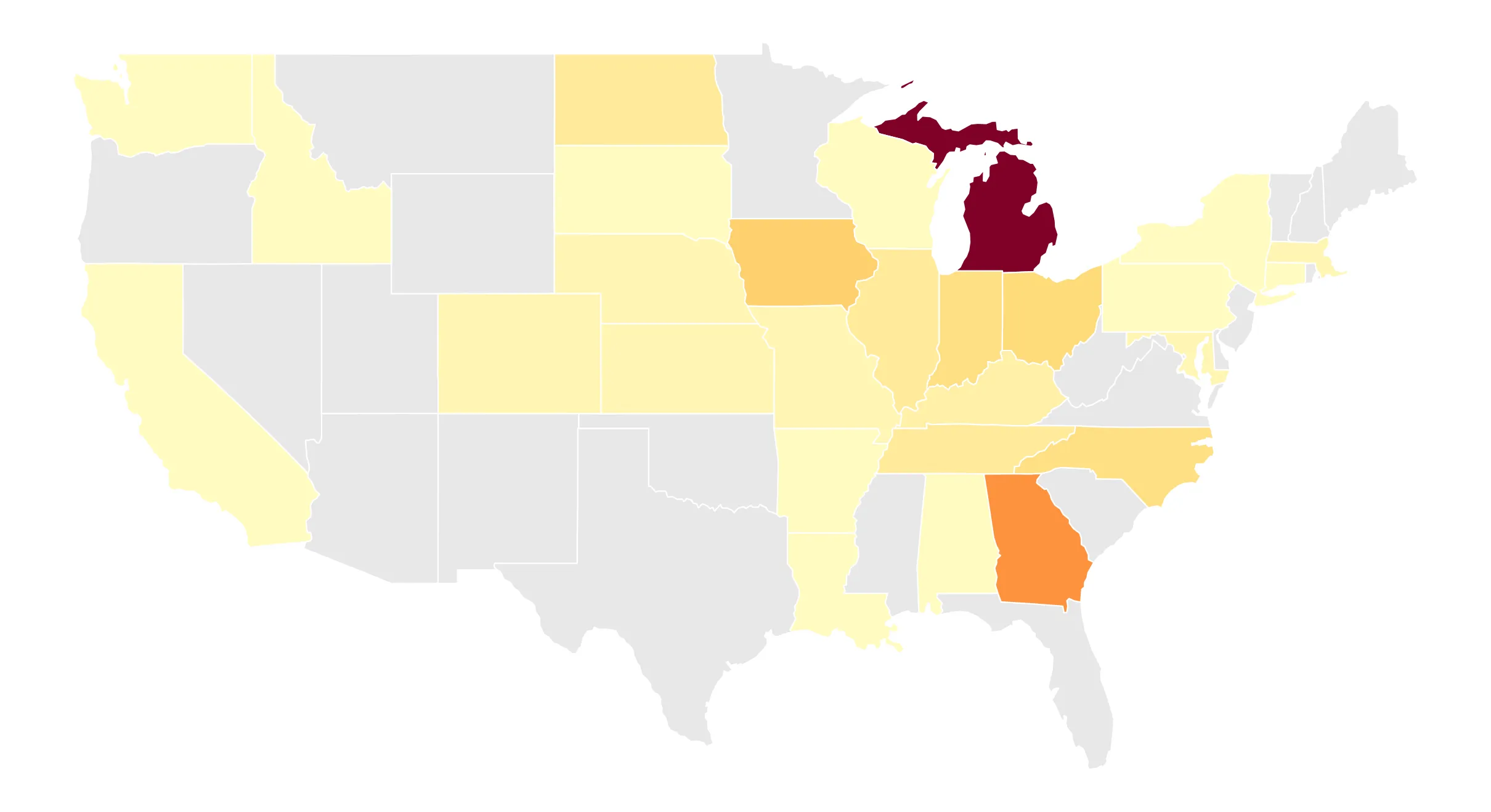
New research identifies 116 infrastructure development moratoria across 30 states, providing the first comprehensive cross-sector survey of how communities are responding to the rapid deployment of data centers, renewables, and battery storage.
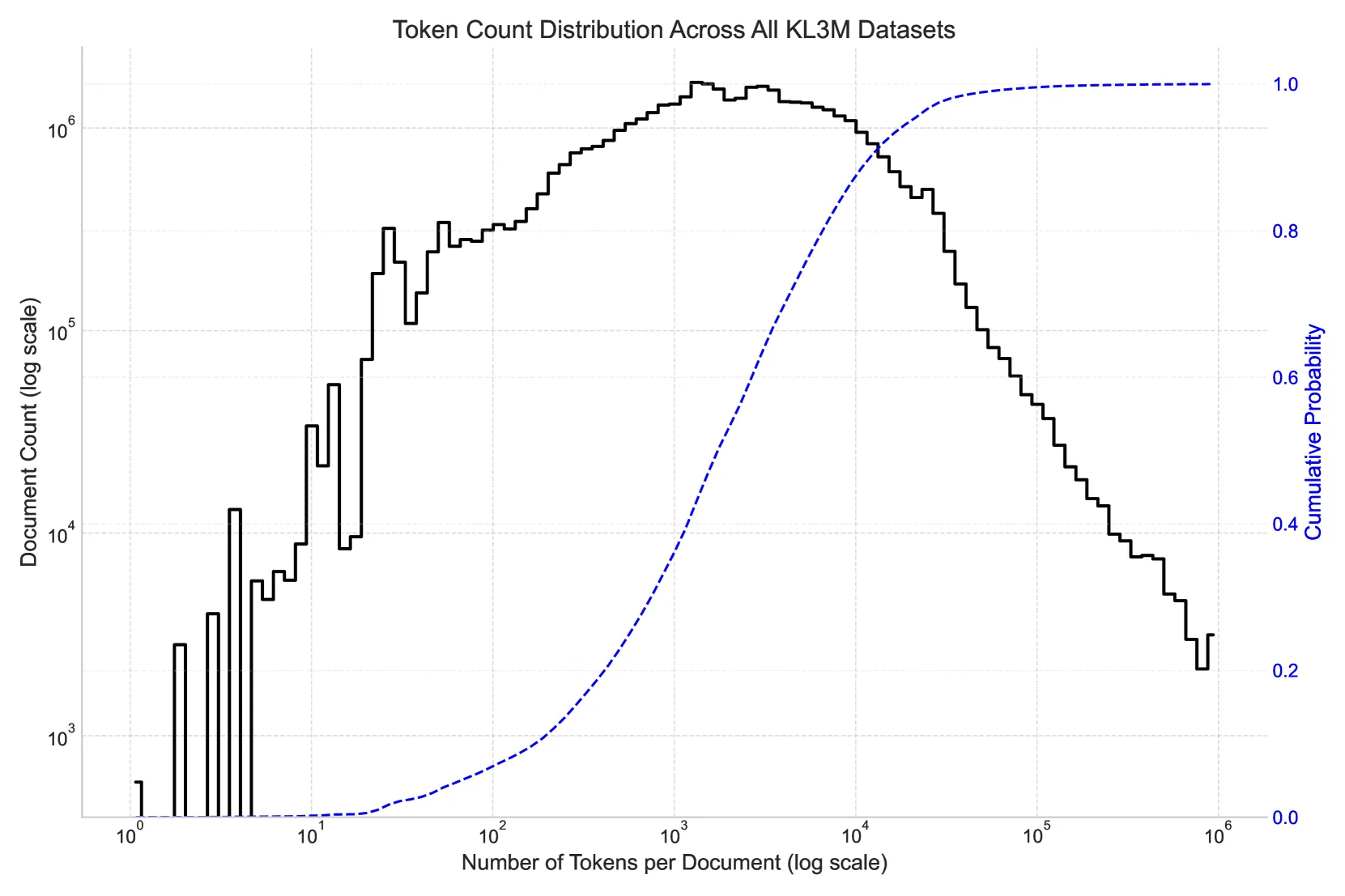
Introducing the KL3M Data Project: a comprehensive collection of legally sound training resources for large language models spanning 132+ million documents.
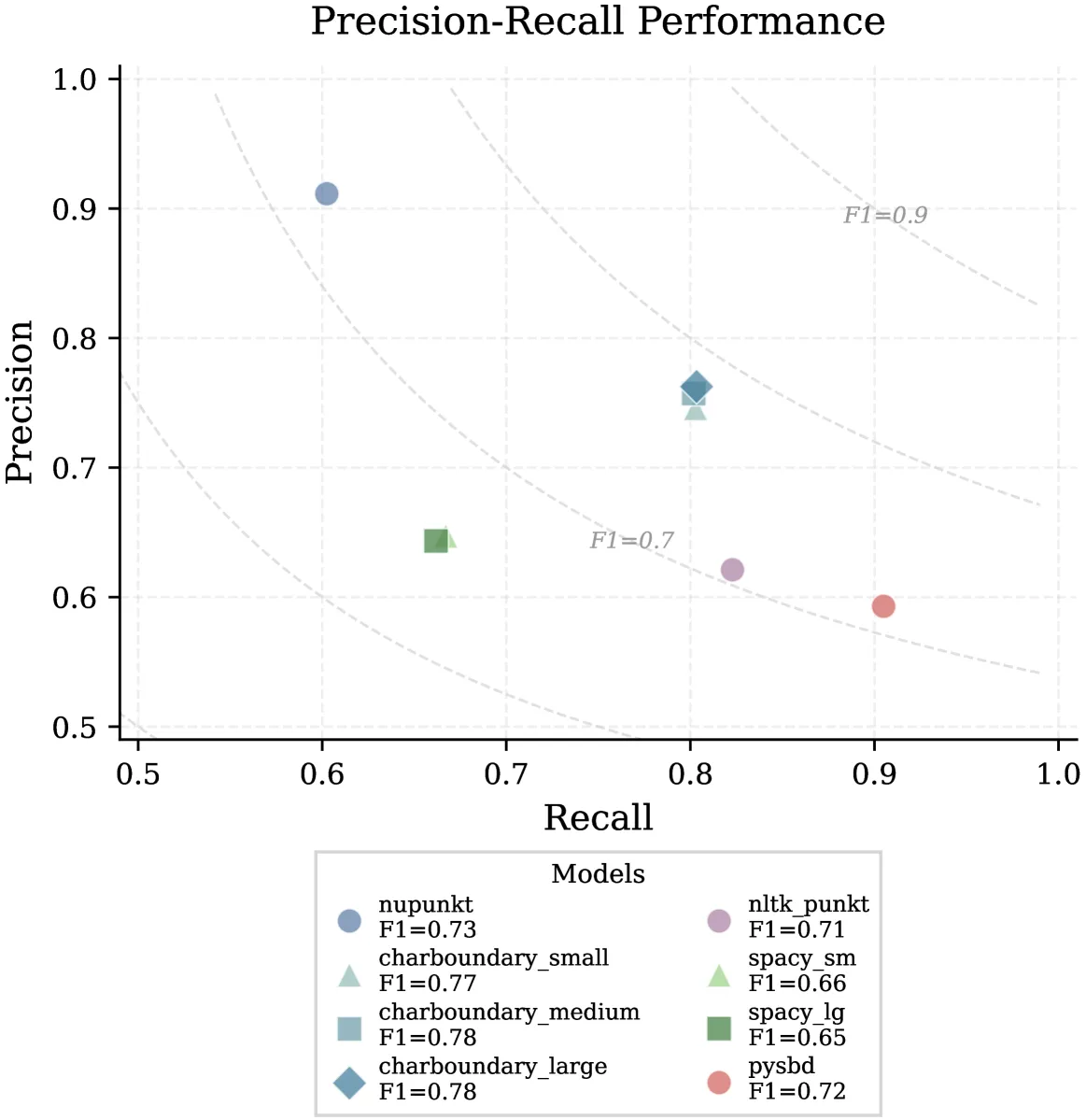
Introducing NUPunkt and CharBoundary: two specialized libraries that dramatically improve sentence boundary detection in legal documents.

Our research demonstrates how specialized tokenizers can achieve up to 83% efficiency gains for domain-specific terminology while maintaining semantic coherence.
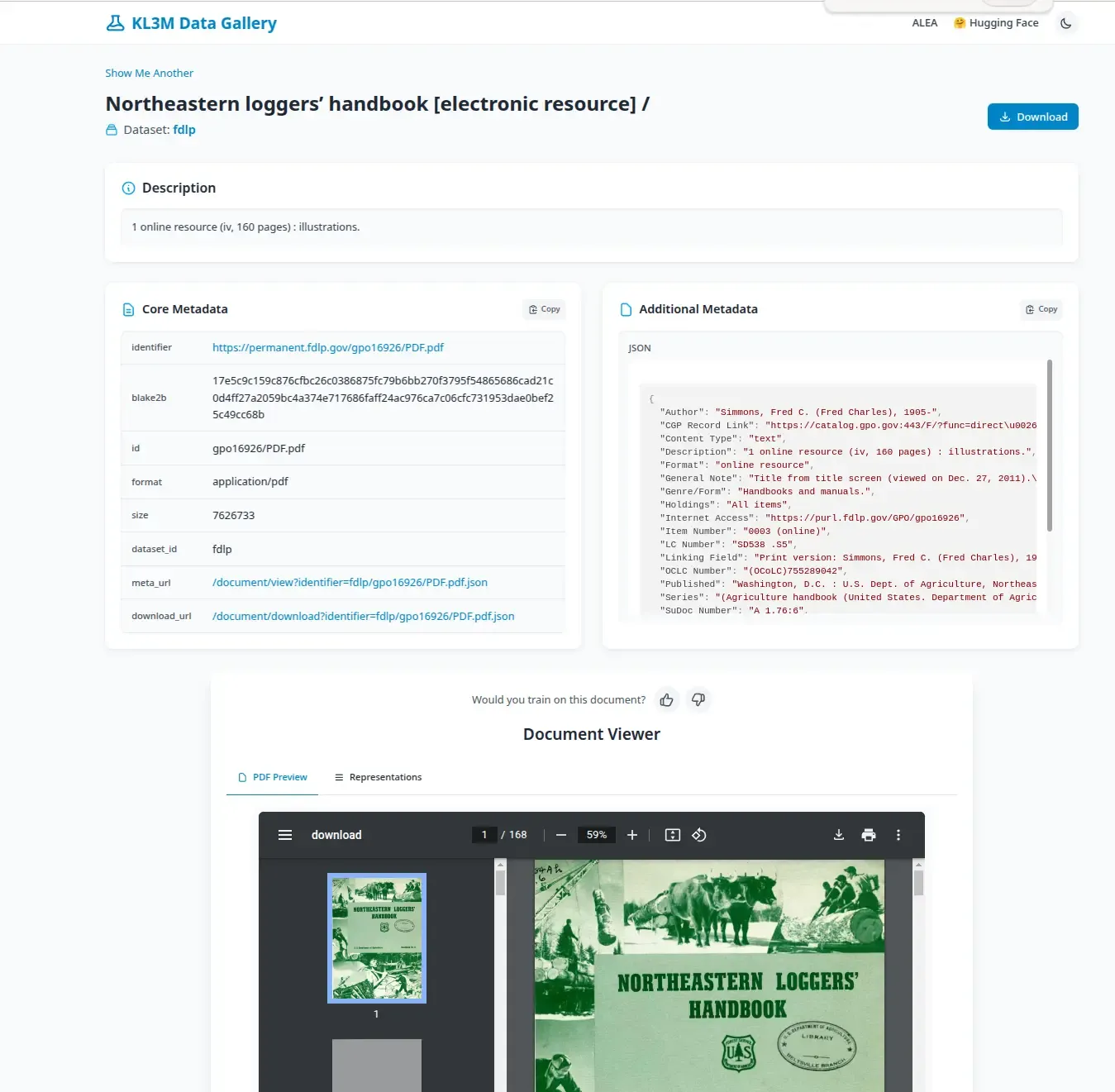
Exploring Clean Data with the KL3M Data Gallery
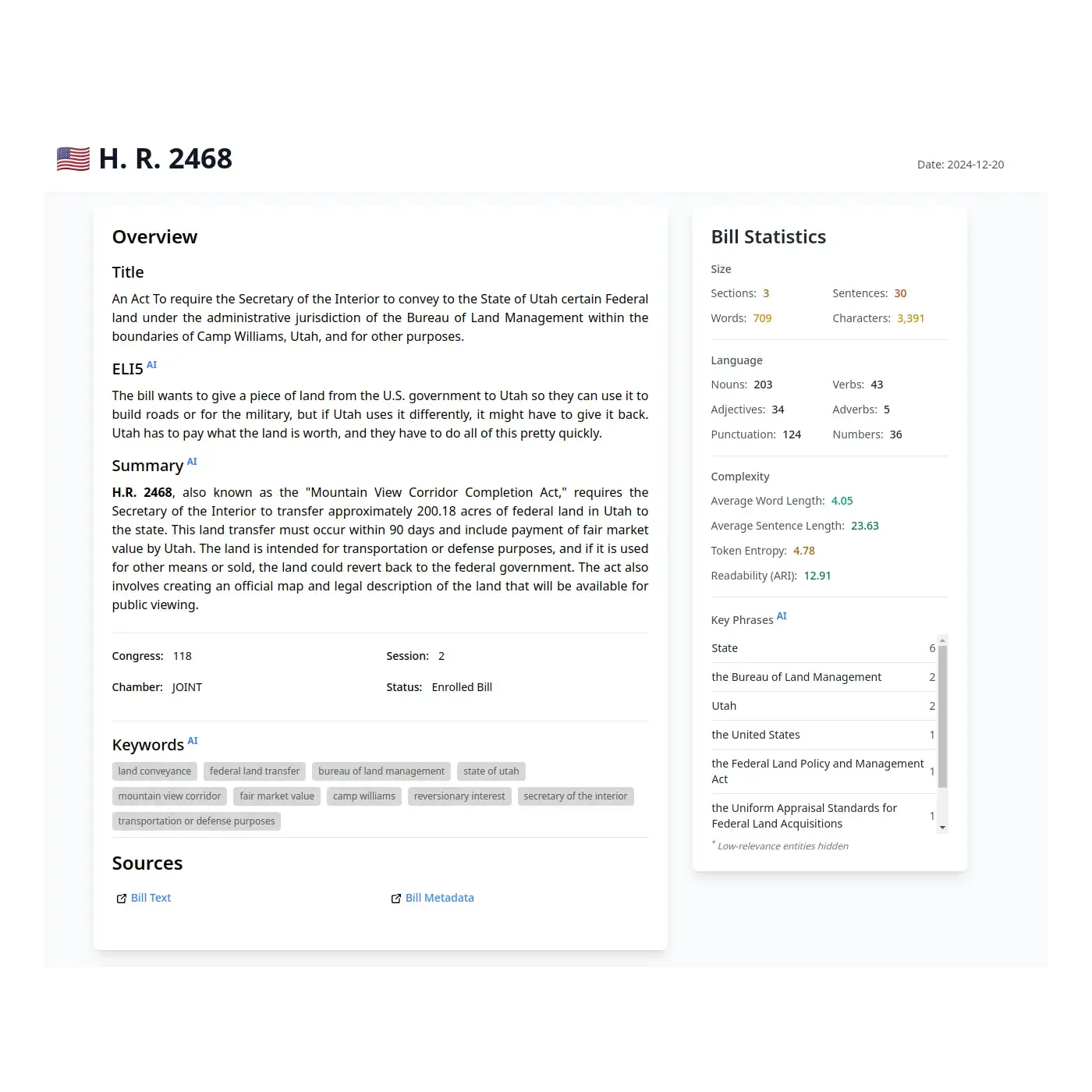
Announcing the launch of usbills.ai - an open platform for analyzing US federal legislation
Our first Fairly Trained L-certified models are now publicly available.

Artificial intelligence is changing our world. But will it be for the better?
Don't be shy. We'd love to hear from you.