Projects and initiatives that we've released or are currently working on.
A chronological showcase of our most recent projects and initiatives, sorted by release date.
Nuisance Map
An open-source web application helping Michigan residents document and track evidence for nuisance cases involving data centers, solar parks, battery storage, and related construction.
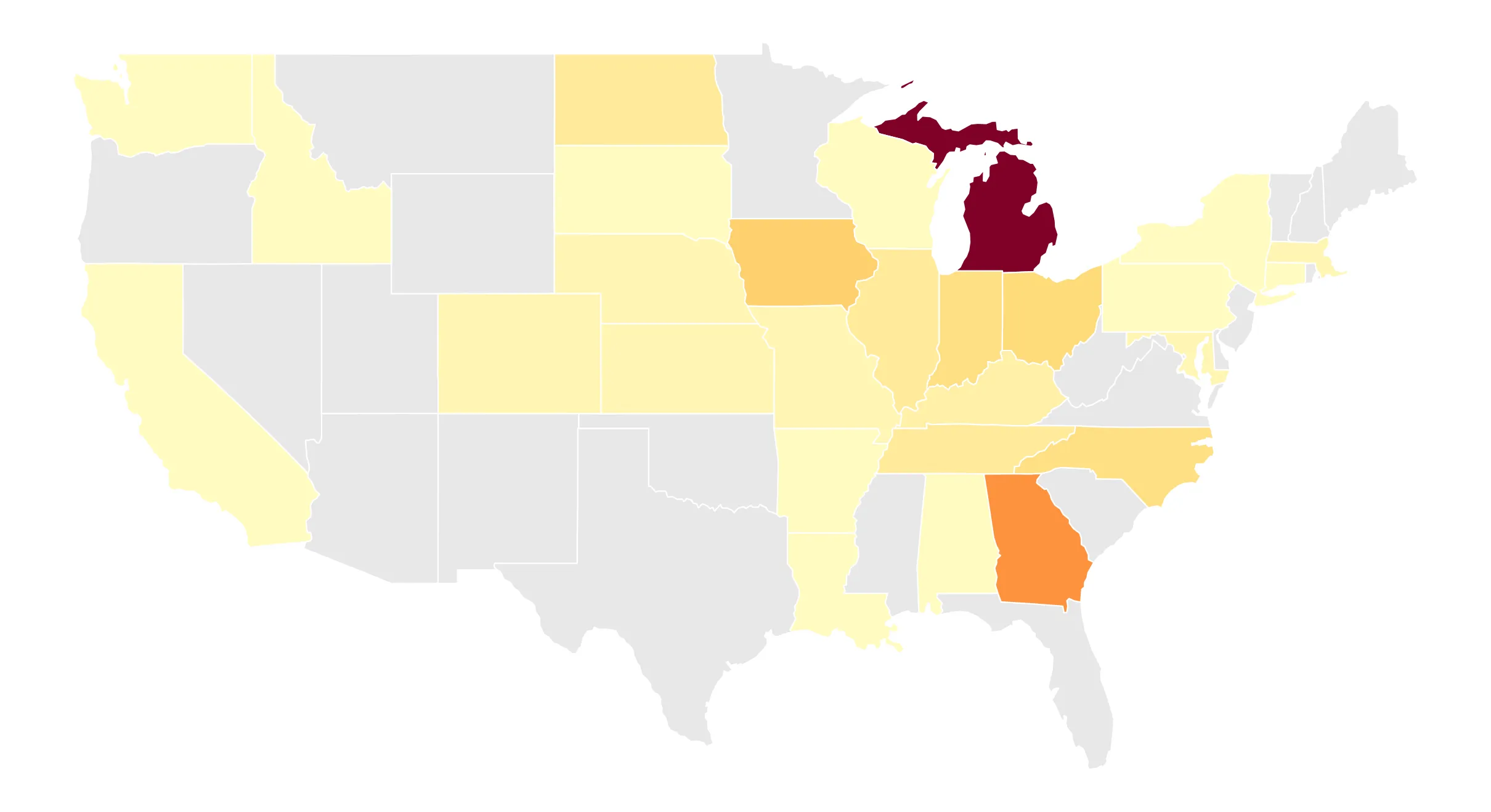
Moratorium Nation
A cross-sector survey of 116 infrastructure development moratoria across 30 U.S. states.
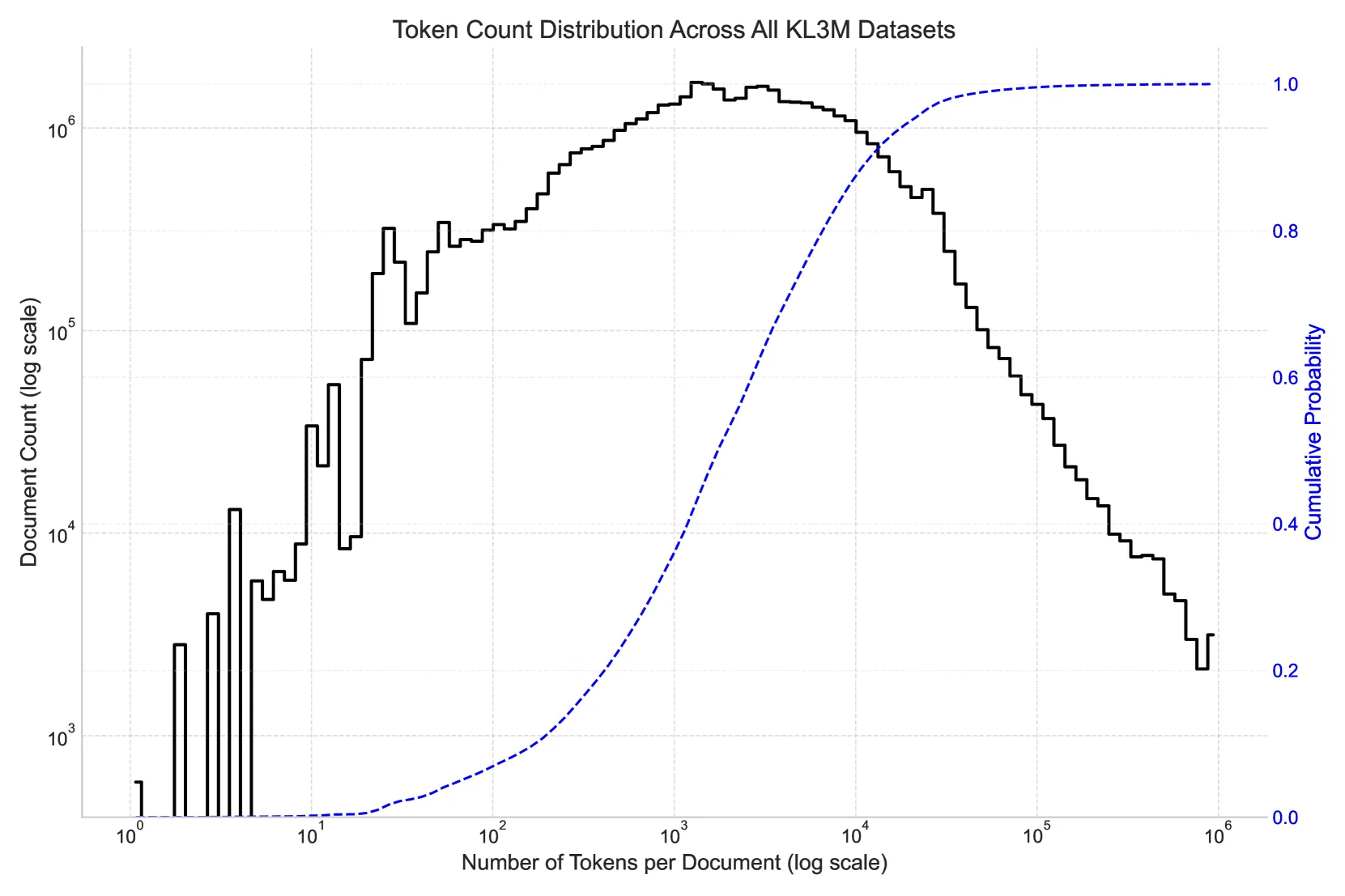
KL3M Data Project
Copyright-clean training resources for large language models across legal, regulatory, and government domains.
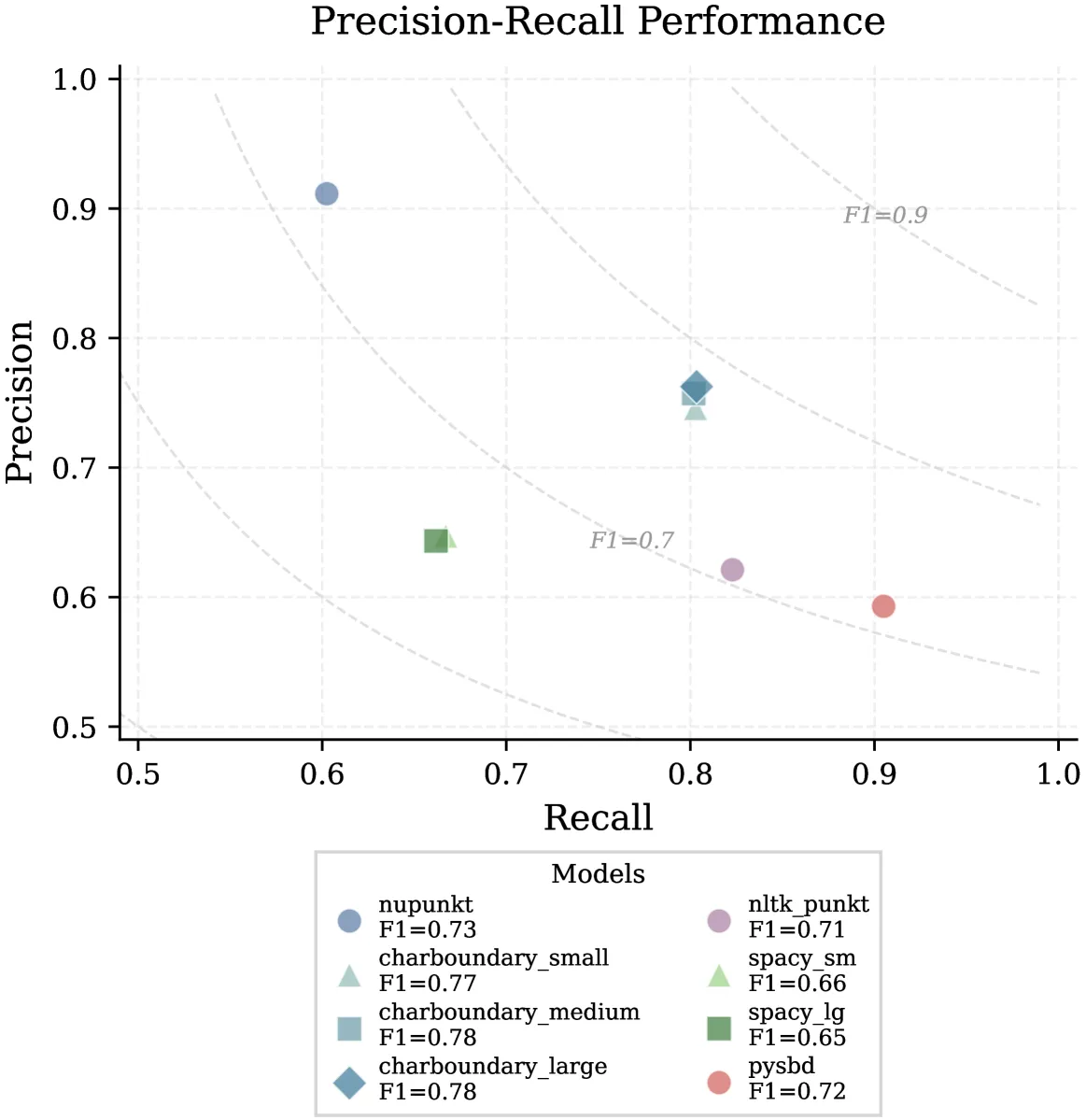
Legal Sentence Boundary Detection
Precision tools for legal text analysis with NUPunkt and CharBoundary libraries.

KL3M Tokenizers
Domain-specific tokenizers achieving up to 83% efficiency gains for legal and financial NLP
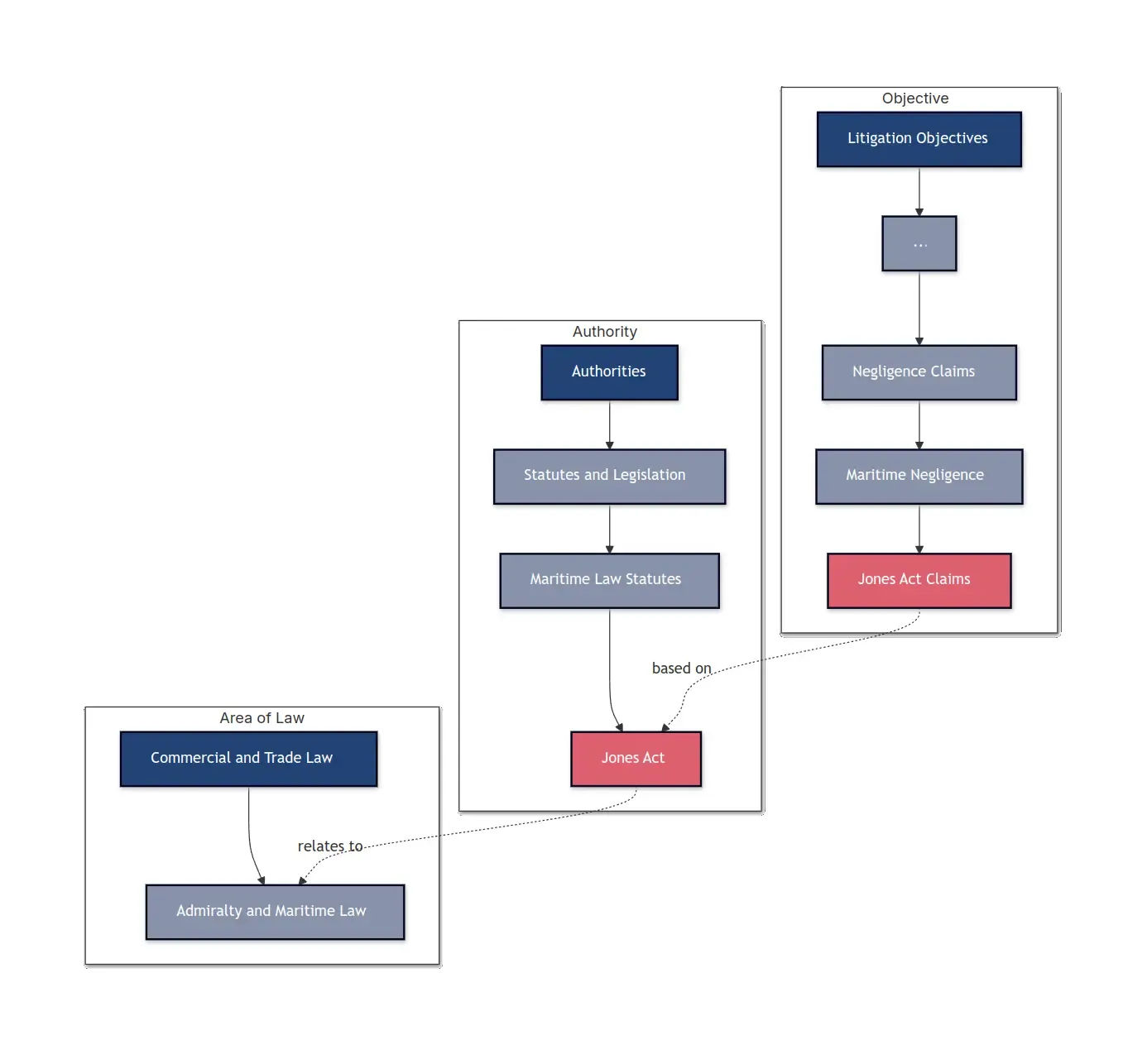
FOLIO - Federated Open Legal Information Ontology
Creating and supporting open knowledge graphs for legal
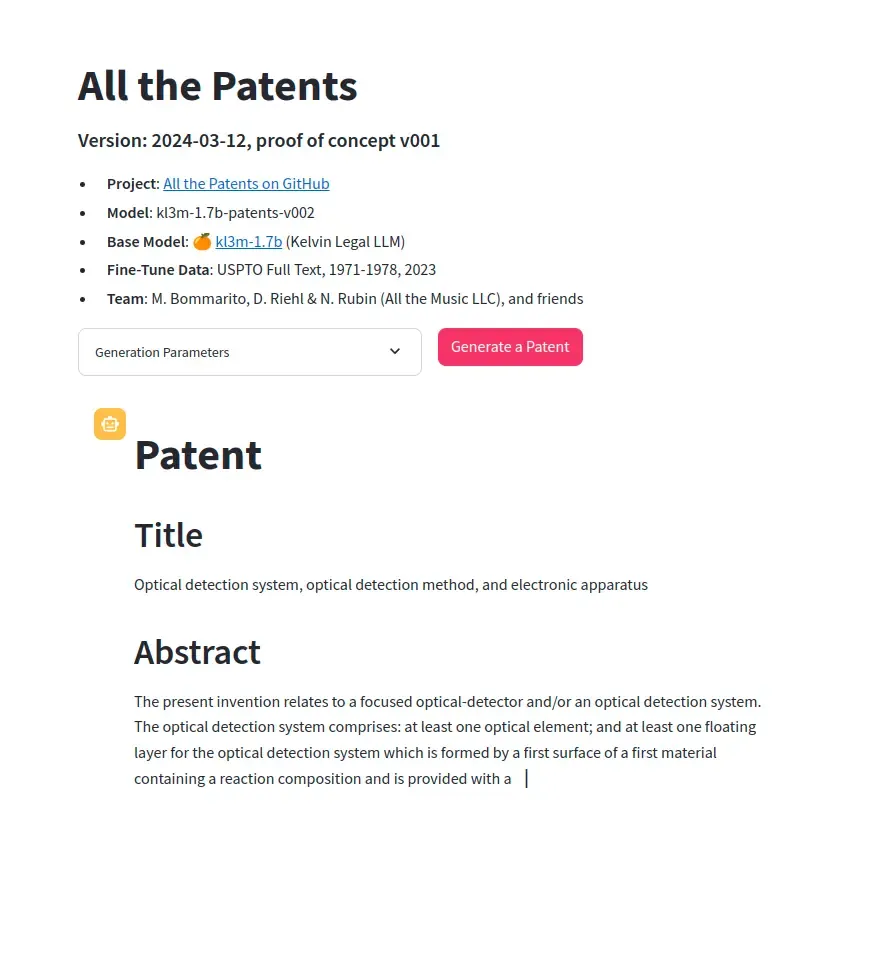
All the Patents
Generating and publishing obvious inventions to improve the patent system
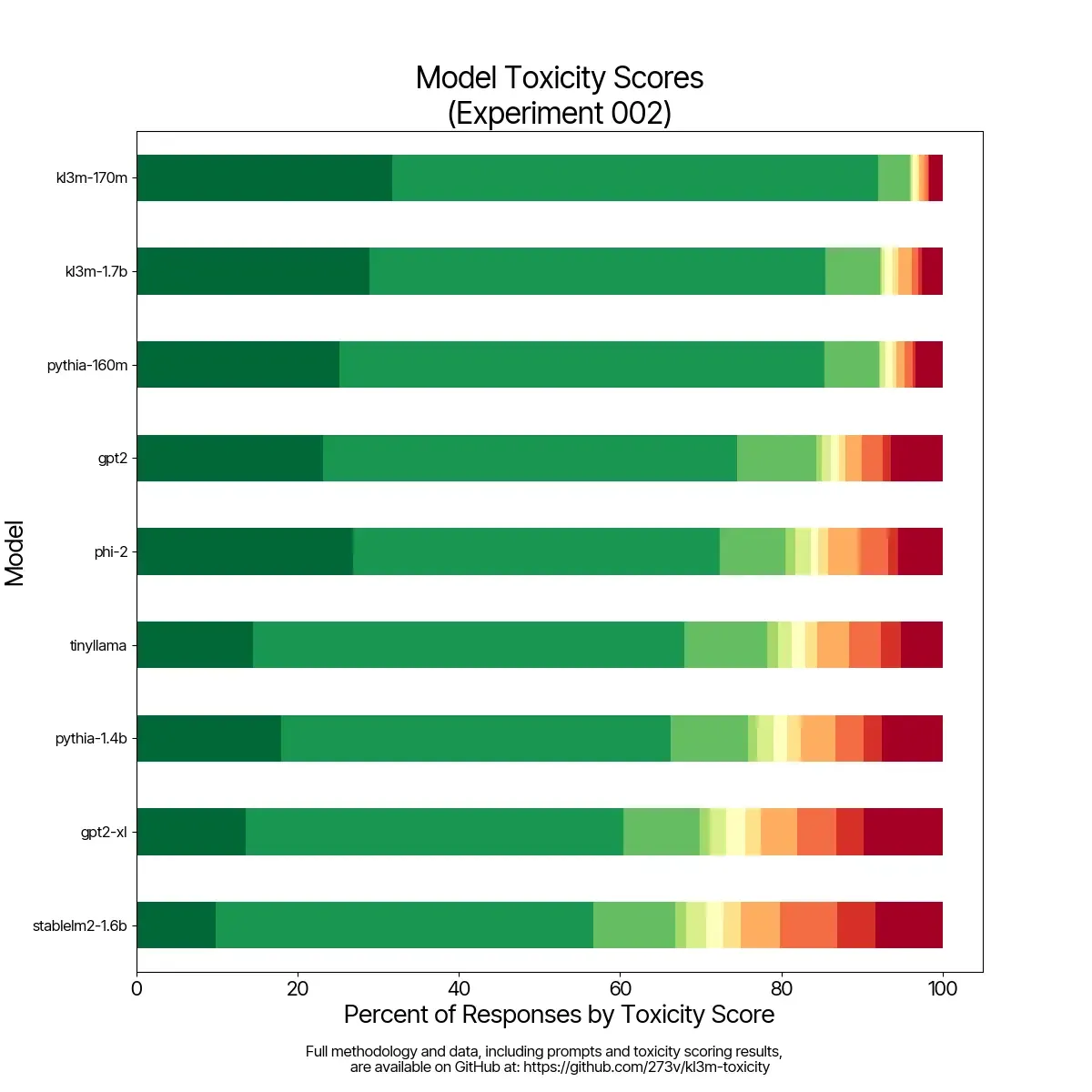
KL3M Toxicity
Toxicity analysis
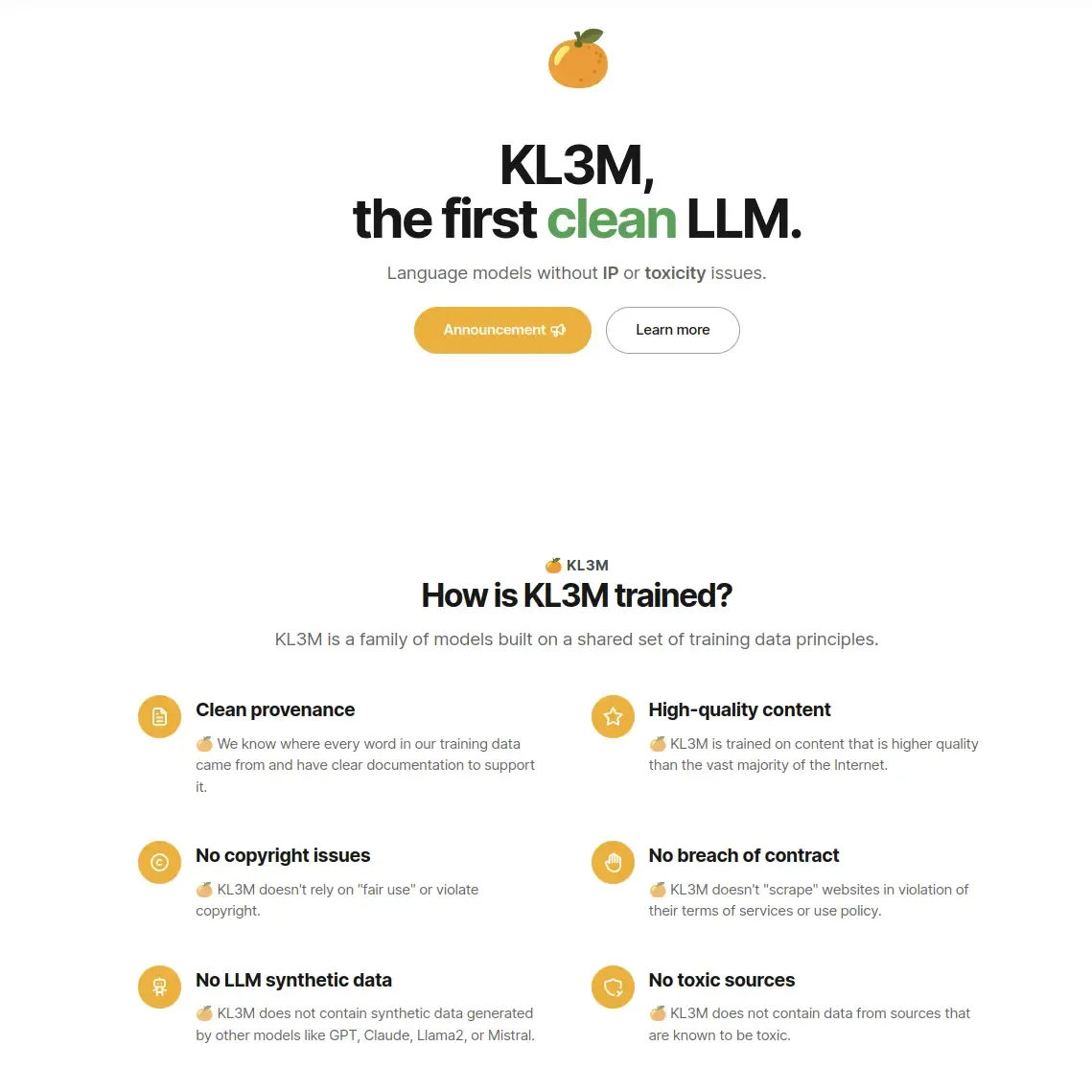
KL3M
The first LLM to receive the Fairly Trained certification.
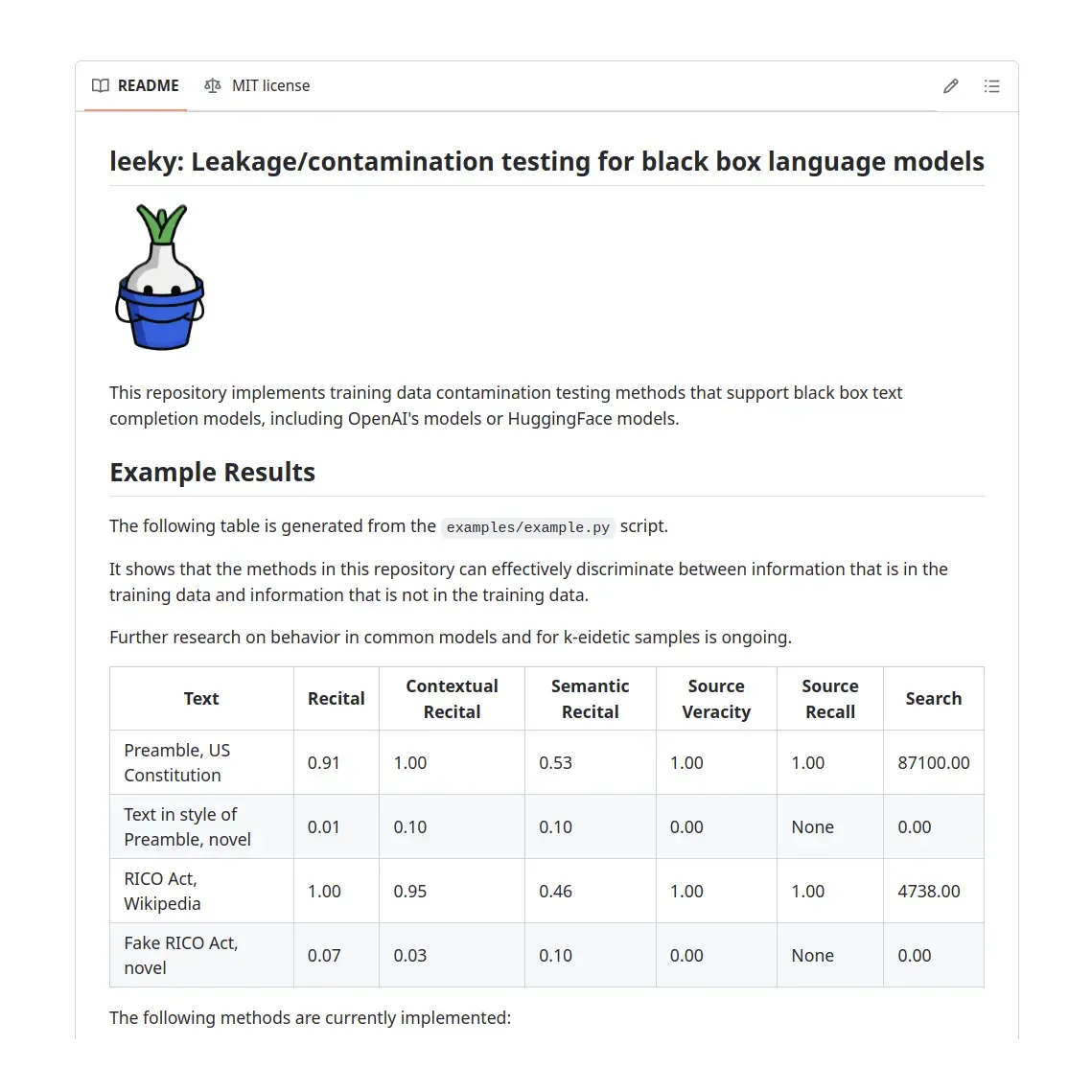
leeky
A Python library to test for training data contamination on black box models.
Don't be shy. We'd love to hear from you.