Supporting socially, economically, and environmentally sustainable futures through open research and education.

A future built on
cooperation and contracts.
AI has the potential to harm society, the economy, and the environment.
It also has the potential to accelerate social, economic, and scientific progress.
While there are many paths forward, we believe that legal and ethical frameworks are the best tools we have to ensure that our shared future is socially, economically, and environmentally sustainable.
Collecting, enriching, and open-sourcing data to support the legal and ethical development and use of AI systems.
More →Conducting technical research related to the legal and ethical use of AI systems.
More →Conducting empirical policy research related to the legal and ethical use of AI systems.
More →Providing educational resources and programs related to the legal and ethical use of AI systems.
More →Partnering to support physical and digital communities focused on legal and ethical AI, and helping communities engage with AI-related development for more fair, sustainable outcomes.
More →
Nuisance Map
An open-source web application helping Michigan residents document and track evidence for nuisance cases involving data centers, solar parks, battery storage, and related construction.
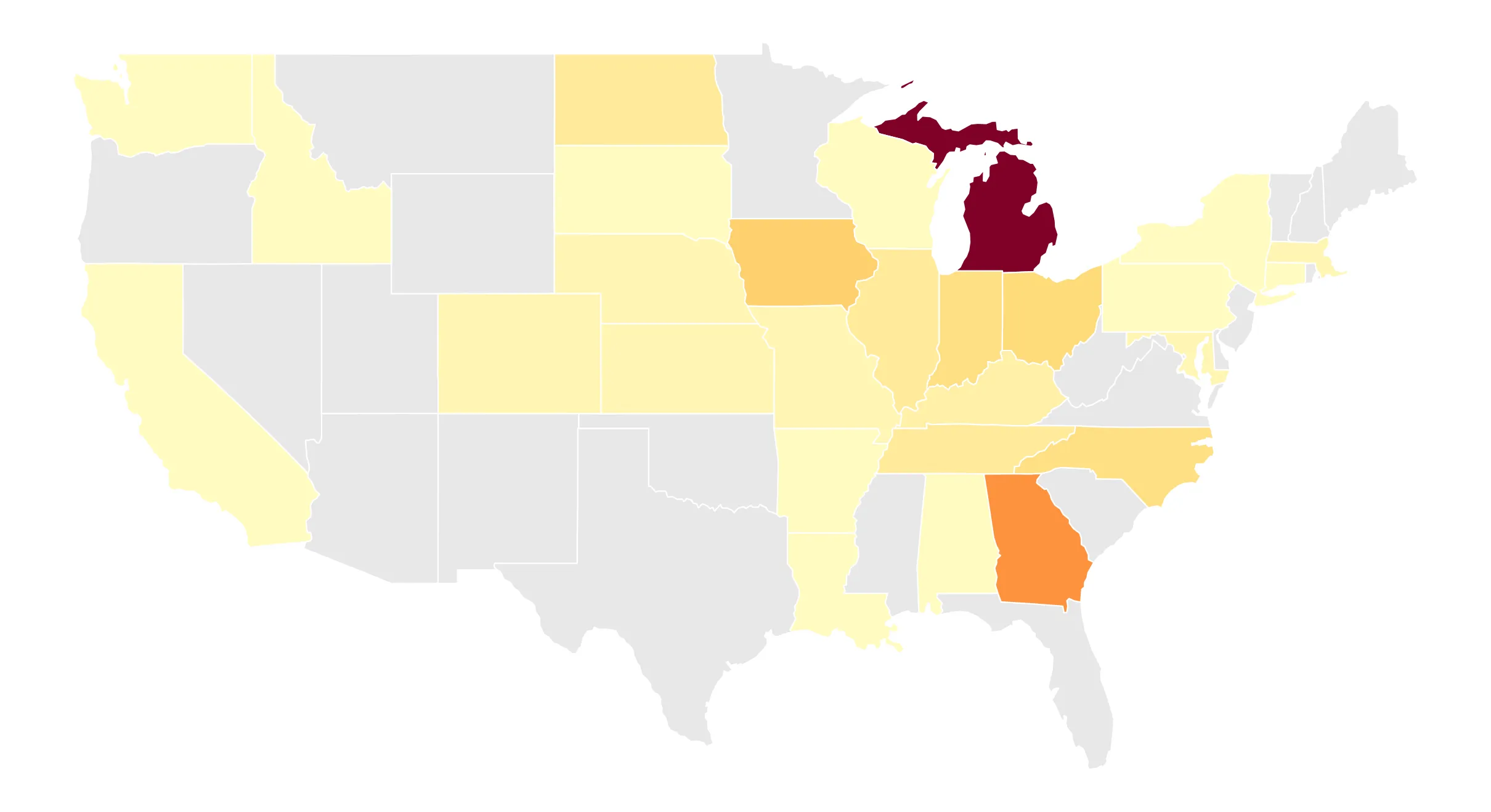
Moratorium Nation
A cross-sector survey of 116 infrastructure development moratoria across 30 U.S. states.
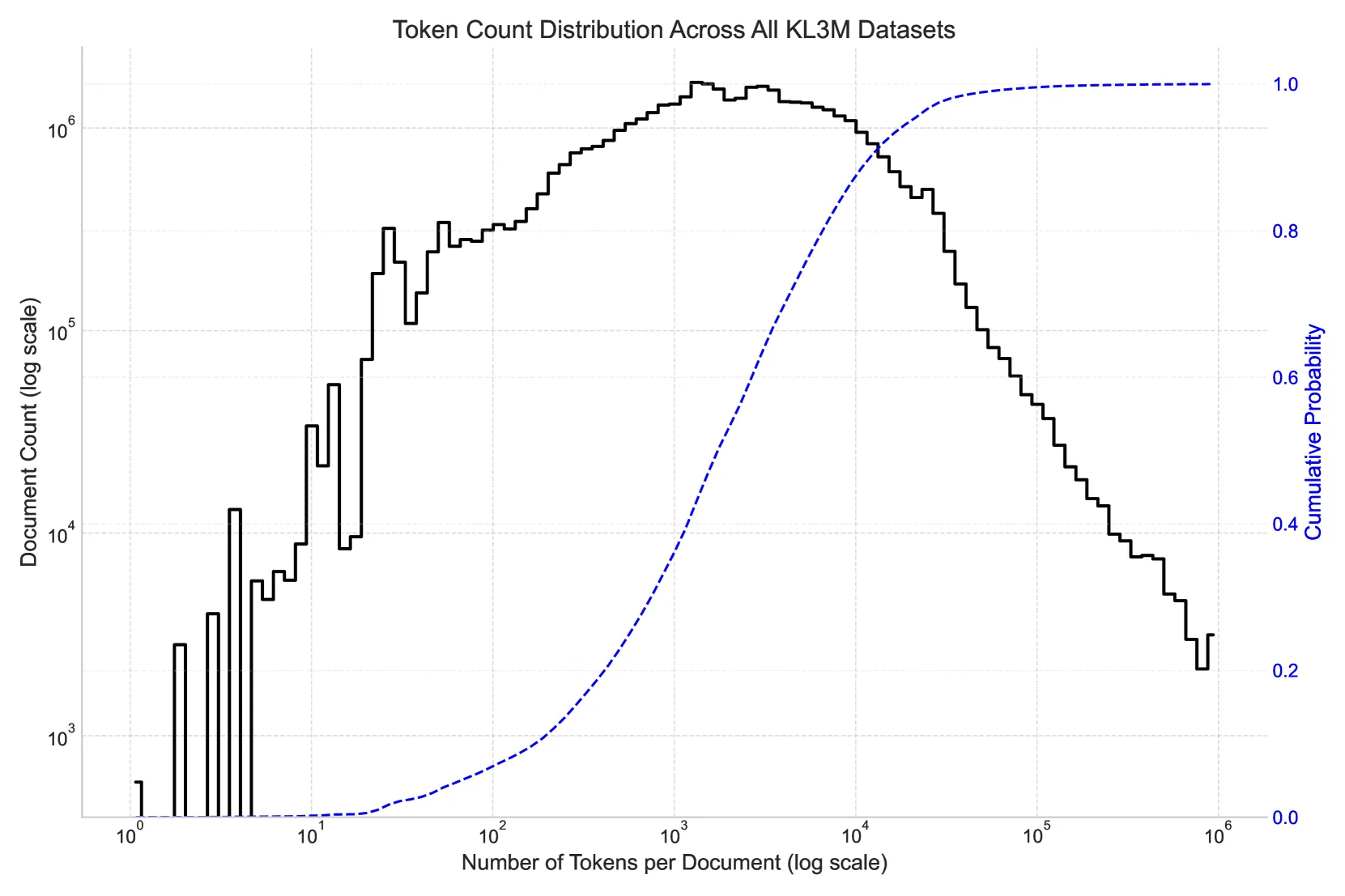
KL3M Data Project
Copyright-clean training resources for large language models across legal, regulatory, and government domains.
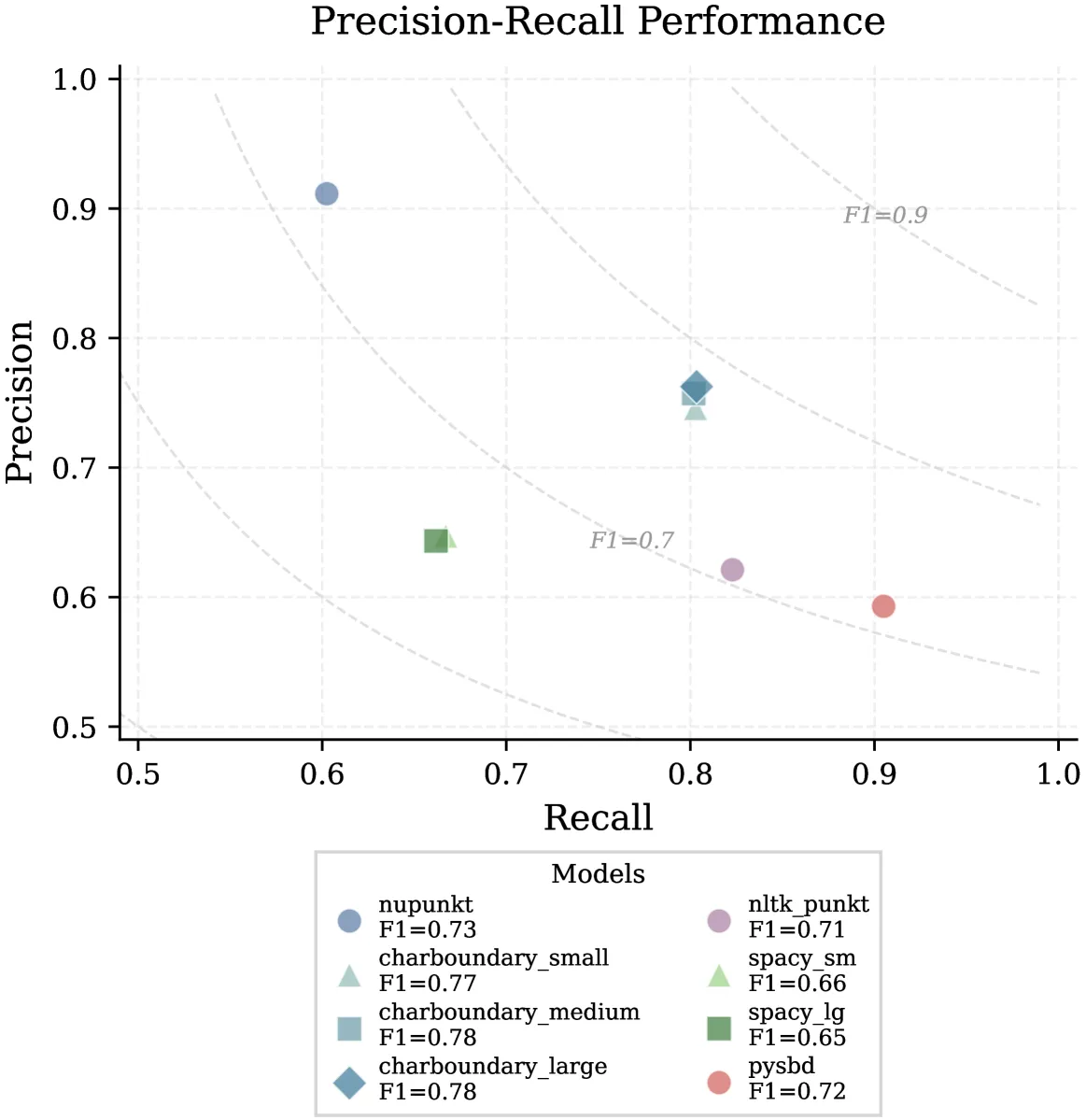
Legal Sentence Boundary Detection
Precision tools for legal text analysis with NUPunkt and CharBoundary libraries.

KL3M Tokenizers
Domain-specific tokenizers achieving up to 83% efficiency gains for legal and financial NLP
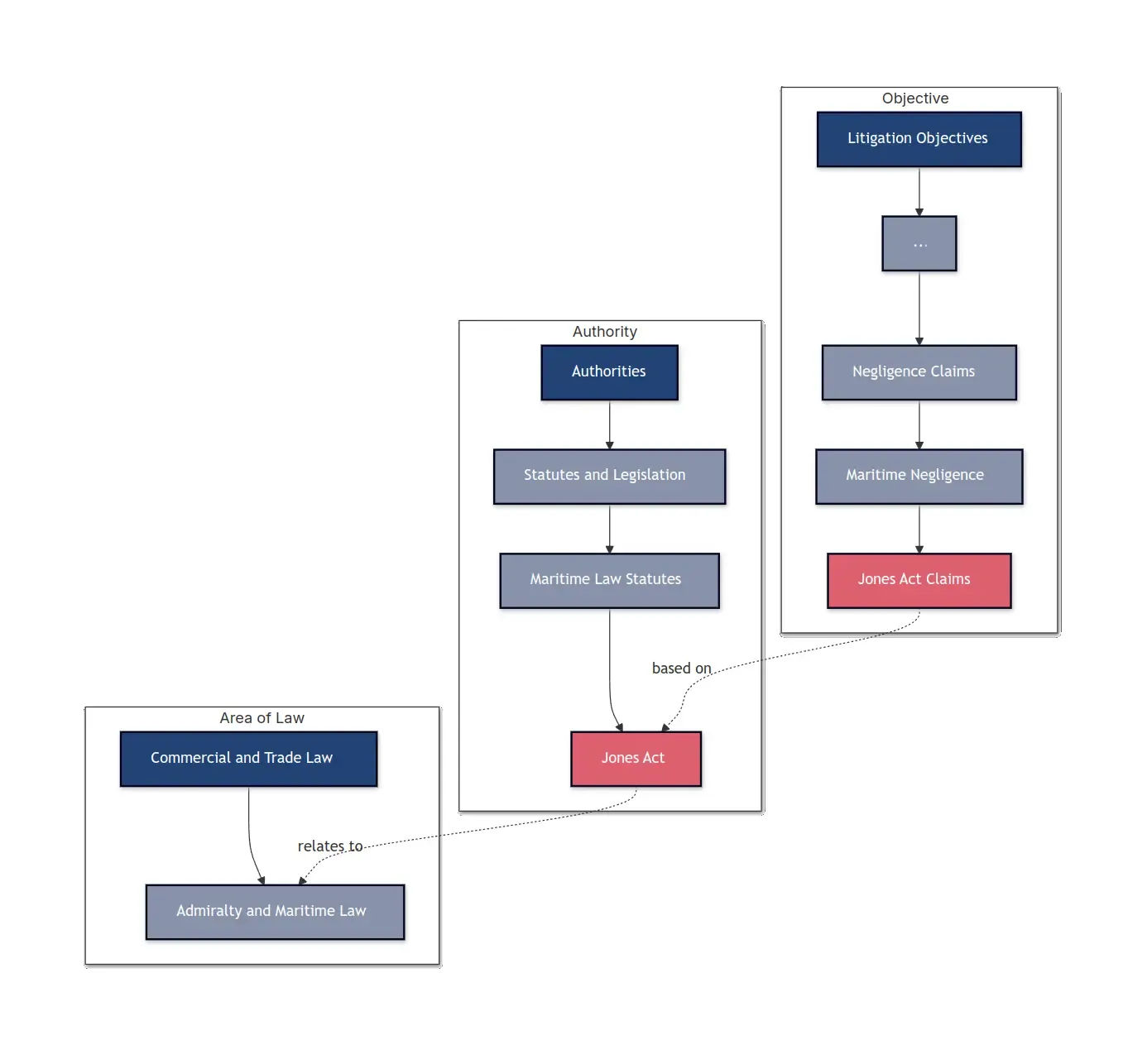
FOLIO - Federated Open Legal Information Ontology
Creating and supporting open knowledge graphs for legal

Let's build a better future together.
We are always looking for new opportunities to collaborate with organizations and individuals who share our vision for a better future.
Here are some examples of how we can work together:
Don't be shy. We'd love to hear from you.

A new MCP server for AI agents, alongside an updated public API and Python library, make FOLIO's legal ontology easier than ever for courts and legal organizations to adopt.
ALEA Institute launches the Nuisance Map, an open-source tool for Michigan residents to document nuisance impacts from data centers and infrastructure development, as part of an expanded community engagement initiative focused on transparency and balanced development.

The ALEA Institute has received its official IRS determination letter granting 501(c)(3) tax-exempt status as a public charity, with an effective date of August 15, 2024.
New research identifies 116 infrastructure development moratoria across 30 states, providing the first comprehensive cross-sector survey of how communities are responding to the rapid deployment of data centers, renewables, and battery storage.